Disk Layout:Dealing with Failures
Contents
17. Disk Layout:Dealing with Failures#
17.1. Consistency and Journaling#
Unlike in-memory structures, data structures on disk must survive system crashes, whether due to hardware reasons (e.g., power failure) or software failures. The problem is compounded by the fact that operating systems typically cache reads and writes to increase performance, so that writes to the disk may occur in a much different order than that in which they were issued by the file system code.
In its simplest form, the problem is that file system operations often involve writing to multiple disk blocks—for example, moving a file from one directory to another requires writing to blocks in the source and destination directories, while creating a file writes to the block and inode allocation bitmaps, the new inode, the directory block, and the file data block or blocks1. If some, but not all, of these writes occur before a crash, the file system may become inconsistent—i.e. in a state not achievable through any legal sequence of file system operations, where some operations may return improper data or cause data loss.
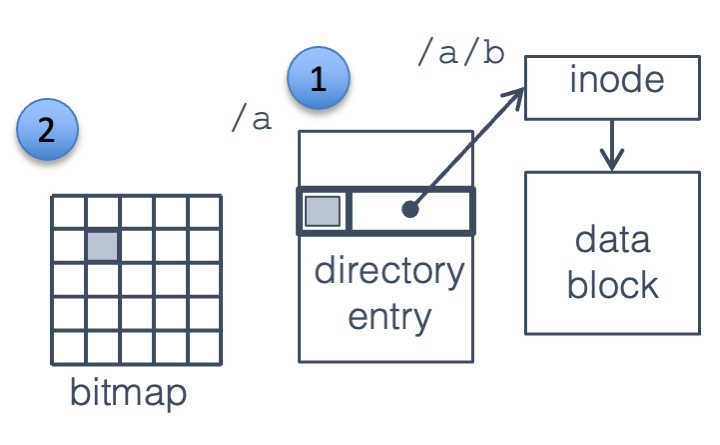
Fig. 17.1 File, directory, bitmap#
For a particularly vicious example, consider deleting the file /a/b as
shown in
Fig. 17.1, which requires the following actions:
Clear the directory entry for /a/b. This is done by marking the entry as unused and writing its block back to the directory.
Free the file data block, by clearing the corresponding entry in the block allocation bitmap
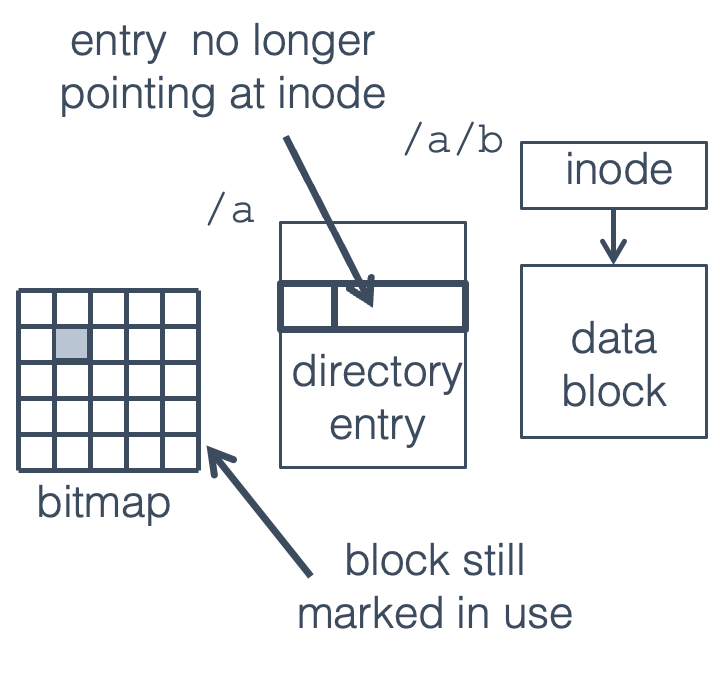
Fig. 17.2 Directory block written before crash#
This results in two disk blocks being modified and written back to disk; if the blocks are cached and written back at a later point in time they may be written to disk in any order. (This doesn’t matter for running programs, as when they access the file system the OS will check cached data before going to disk.)
If the system crashes (e.g., due to a power failure) after one of these blocks has been written to disk, but not the other, two cases are possible:
The directory block is written, but not the bitmap. The file is no longer accessible, but the block is still marked as in use. This is a disk space leak (like a memory leak), resulting in a small loss of disk space but no serious problems.
The bitmap block is written, but not the directory. Applications are still able to find the file, open it, and write to it, but the block is also available to be allocated to a new file or directory. This is much more serious.
If the same block is re-allocated for a new file (/a/c in this
case), we now have two files sharing the same data block, which is
obviously a problem. If an application writes to /a/b it will also
overwrite any data in /a/c, and vice versa. If /a/c is a directory
rather than a file things are even worse—a write to /a/b will wipe
out directory entries, causing files pointed to by those entries to be
lost. (The files themselves won’t be erased, but without directory entries pointing to them there won’t be any way for a
program to access them.)
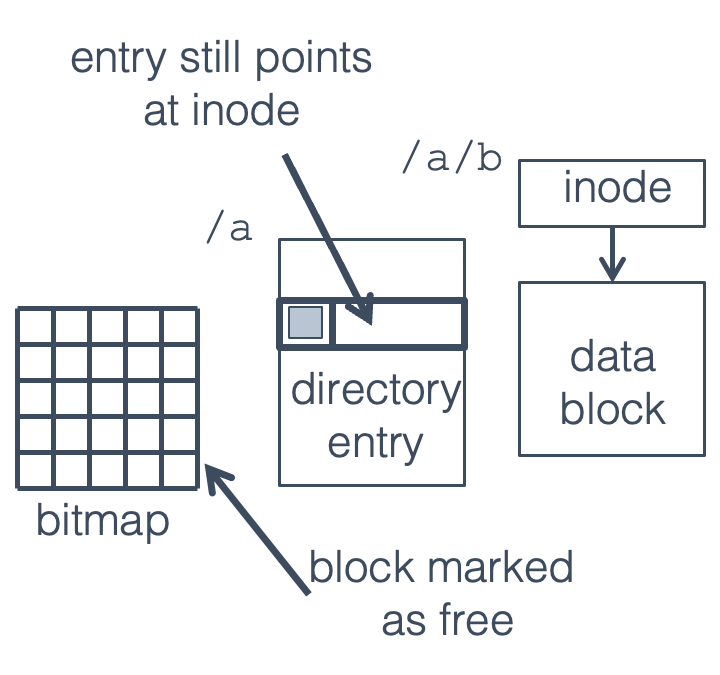
Fig. 17.3 Bitmap block written before crash#
This can be prevented by writing blocks in a specific order—for instance, in this case the directory entry could always be cleared before the block is marked as free, as shown in Fig. 17.4, so that in the worst case a crash might cause a few data blocks to become unusable. Unfortunately, this is very slow, as these writes must be done synchronously, waiting for each write to complete before issuing the next one.
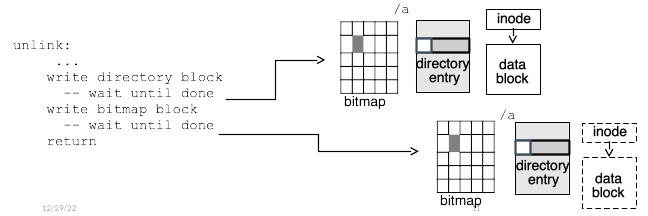
Fig. 17.4 Synchronous disk writes for ext2 consistency.#
Fsck / chkdsk:
An alternative to the overhead of synchronous file system writes is to allow the OS to write blocks back to disk in any order, but detect and recover from any inconsistencies that occur due to an untimely crash. One way to do this is to run a disk checking
routine every time the system boots after a crash. Earlier in Section 13 we mentioned the file system superblock contained information to help with recovery. In particular, the superblock contains a dirty flag, which is set to true when the file system is mounted, and set to false when the file system is cleanly unmounted. In both cases, these changes to the superblock dirty flag are written to disk. When a
machine boots, or a file system is mounted later, if the file system is marked dirty, fsck (or chkdsk
in Windows) is run to repair any problems.
In particular, the Unix file system checker performs the following checks and corrections:
Blocks and sizes. Each allocated inode is checked to see that (a) the number of blocks reachable through direct and indirect pointers is consistent with the file size in the inode, (b) all block pointers are within the valid range for the volume, and (c) no blocks are referenced by more than one inode.
Pathnames. The directory tree is traversed from the root, and each entry is checked to make sure that it points to a valid inode of the same type (directory / file / device) as indicated in the entry.
Connectivity. Verifies that all directory inodes are reachable from the root.
Reference counts. Each inode holds a count of how many directory entries (hard links) are pointing to it. This step validates that count against the count determined by traversing the directory tree, and fixes it if necessary.
“Cylinder Groups”. The block and inode bitmaps are checked for consistency. In particular, are all blocks and inodes reachable from the root marked in use, and all unreachable ones marked free?
“Salvage Cylinder Groups”. Free inode and block bitmaps are updated to fix any discrepancies.
This is a lot of work, and involves a huge number of disk seeks. On a
large volume it can take hours to run. Note that full recovery may
involve a lot of manual work; for instance, if fsck finds any files
without matching directory entries, it puts them into a lost+found
directory with numeric names, leaving a human (i.e., you) to figure out
what they are and where they belong.
Checking disks at startup worked fine when disks were small, but as they got larger (and seek times didn’t get faster) it started taking longer and longer to check a file system after a crash. Uninterruptible power supplies help, but not completely, since many crashes are due to software faults in the operating system. The corruption problem you saw was due to inconsistency in the on-disk file system state. In this example, the free space bitmap did not agree with the directory entry and inode. If the file system can ensure that the on-disk data is always in a consistent state, then it should be possible to prevent losing any data except that being written at the exact moment of the crash.
Performing disk operations synchronously (and carefully ordering them in the code) will prevent inconsistency, but as described above, imposes excessive performance costs. Instead a newer generation of file systems, termed journaling file systems, has incorporated mechanisms which add additional information which can be used for recovery, allowing caching and efficient use of the disk, while maintaining a consistent on-disk state.
17.2. Journaling#
Most modern file systems (NTFS, ext3, ext4, and various others) use journaling, a variant of the database technique of write-ahead logging. The idea is to keep a log which records the changes that are going to be made to the file system, before those changes are made. After an entry is written to the log, the changes can be written back in any order; after they are all written, the section of log recording those changes can be freed.
When recovering from a crash, the OS goes through the log and checks that all the changes recorded there have been performed on the file system itself2. Some thought should convince you that if a log entry is written, then the modification is guaranteed to happen, either before or after a crash; if the log entry isn’t written completely then the modification never happened. (There are several ways to detect a half-written log entry, including using an explicit end marker or a checksum; we’ll just assume that it’s possible.)

Fig. 17.5 Step 1: record action in log#
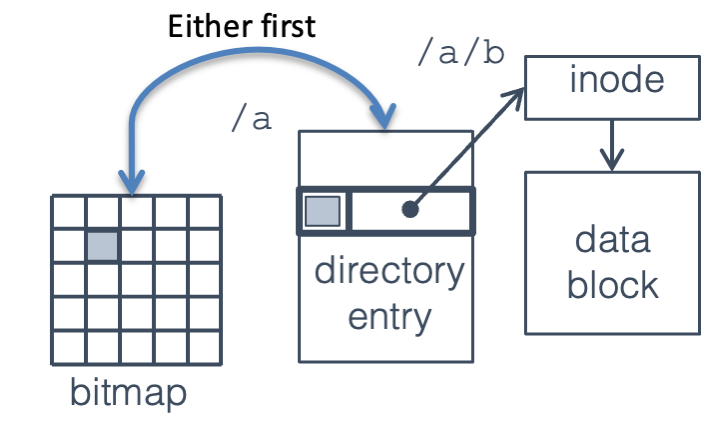
Fig. 17.6 Step 2: write blocks in any order#
Ext3 Journaling: The ext3 file system uses physical block logging: each log entry contains a header identifying the disk blocks which are modified (in the example you saw earlier, the bitmap and the directory entry) and a copy of the disk blocks themselves. After a crash the log is replayed by writing each block from the log to the location where it belongs. If a block is written multiple times in the log, it will get overwritten multiple times during replay, and after the last over-write it will have the correct value.
To avoid synchronous journal writes for every file operation, ext3 uses
batch commit: journal writes are deferred, and multiple writes are
combined into a single transaction. The log entries for the entire batch
are written to the log in a single sequential write, called a
checkpoint. In the event of a crash, any modifications since the last
checkpoint will be lost, but since checkpoints are performed at least
every few seconds, this typically isn’t a problem. (If your program
needs a guarantee that data is written to a file right now, you need
to use the fsync system call to flush data to disk.)
Ext3 supports three different journaling modes:
Journaled: In this mode, all changes (to file data, directories, inodes and bitmaps) are written to the log before any modifications are made to the main file system.
Ordered: Here, data blocks are flushed to the main file system before a journal entry for any metadata changes (directories, free space bitmaps, inodes) is written to the log, after which the metadata changes may be made in the file system. This provides the same consistency guarantees as journaled mode, but is usually faster.
Writeback: In this mode, metadata changes are always written to the log before being applied to the main file system, but data may be written at any time. It is faster than the other two modes, and will prevent the file system itself from becoming corrupted, but data within a file may be lost.
17.3. Log-Structured File Systems#
Log-structured file systems (like LFS in NetBSD, or NetApp WAFL) are an extreme version of a journaled file system: the journal is the entire file system. Data is never over-written; instead a form of copy-on-write is used: modified data is written sequentially to new locations in the log. This gives very high write speeds because all writes (even random ones) are written sequentially to the disk.
Fig. 17.7 compares LFS to ext2, showing a simple file system with two directories (dir1, dir2) and two files (/dir1/file1, /dir2/file2). In ext2 the root directory inode is found in a fixed location, and its data blocks do not move after being allocated; in LFS both inode and data blocks move around—as they are modified, the new blocks get written to the head of the log rather than overwriting the old ones. The result can be seen graphically in the figure—in the LFS image, pointers only point to the left, pointing to data that is older than the block holding a pointer.
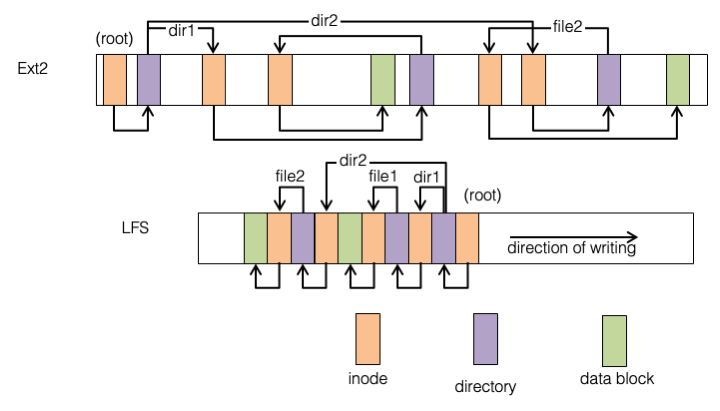
Fig. 17.7 Ext2 vs. Log-structured file system layout#
Unlike ext2 there is no fixed location to find the root directory; this is solved by periodically storing its location in a small checkpoint record in a fixed location in the superblock. (This checkpoint is not shown in the figure, and would be the only arrow pointing to the right.)
When a data block is re-written, a new block with a new address is used. This means that the inode (or indirect block) pointing to the data block must be modified, which means that its address changes.
LFS uses a table mapping inodes to locations on disk, which is updated with the new inode address to complete the process; this table is itself stored as a file. (The astute reader may wonder why this update doesn’t in fact trigger another update to the inode file, leading to an infinite loop. This is solved by buffering blocks in memory before they are written, so that multiple changes can be made.)
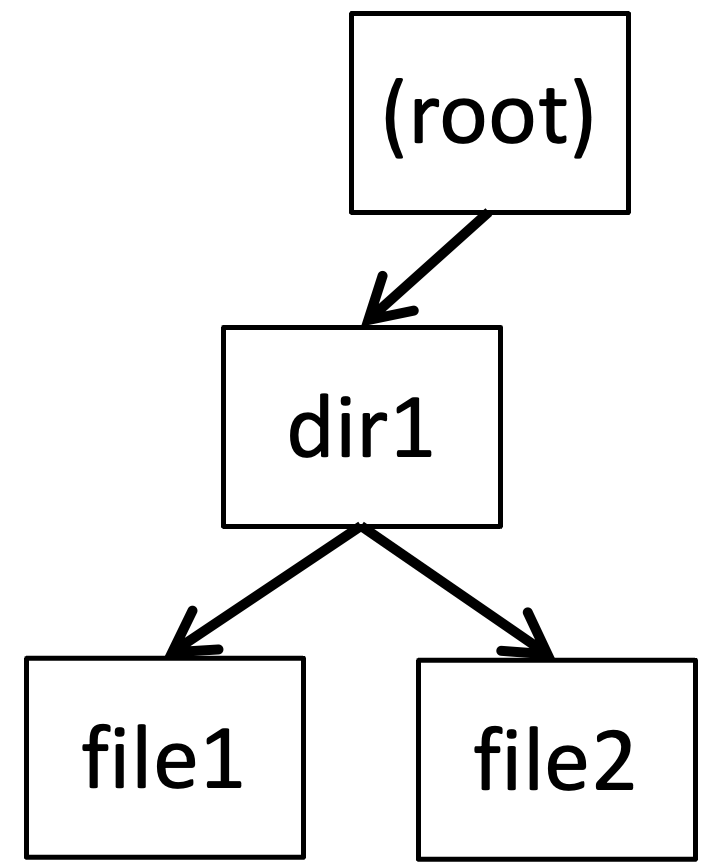
Fig. 17.8 WAFL tree before update#
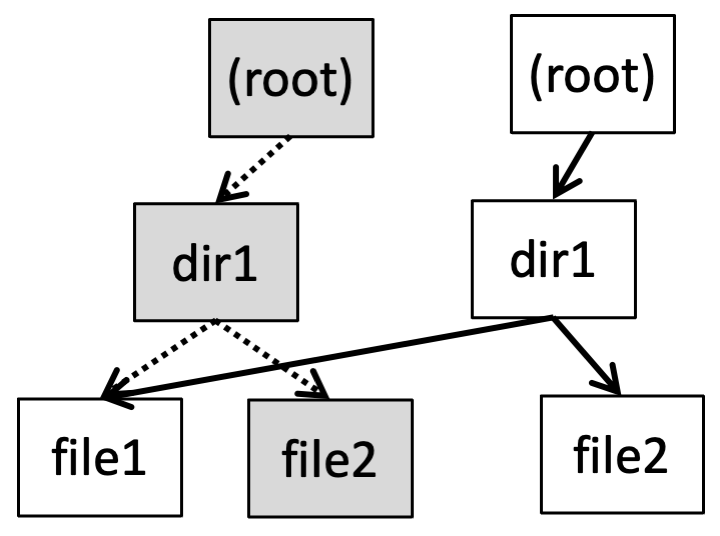
Fig. 17.9 WAFL tree after update#
In WAFL these changes percolate all the way up through directory entries, directory inodes, etc., to the root of the file system, potentially causing a large number of writes for a small modification. (although they’ll still be fairly fast since it’s a single sequential write) To avoid this overhead, WAFL buffers a large number of changes before writing to disk; thus although any single write will modify the root directory, only a single modified copy of the root directory has to be written in each batch.
In Fig. 17.8 and Fig. 17.9 a WAFL directory tree is shown before and after modifying /dir1/file2, with the out-of-date blocks shown in grey. If we keep a pointer to the old root node, then you can access a copy of the file system as it was at that point in time. When the disk fills up, these out-of-date blocks are collected by a garbage collection process, and made available for new writes.
One of the advantages of a log-structured file system is the ability to easily keep snapshots of file system state—a pointer to an old version of the inode table or root directory will give you access to a copy of the file system at the point in time corresponding to that version.