Virtualizing a CPU
Contents
7. Virtualizing a CPU#
When we say “virtualizing” what we mean is actually adding a layer of indirection between the target (in this case the CPU) and the user (the process). In order to do this, we will need a way of pausing the execution of a process while another process runs and then resuming execution later without the process having to be aware of this pause, which means we need to capture all of the state that is relevant to a process in one or more data structures we can use to hold them when the process is not active. When the OS changes the active process on a CPU, we call this a context switch. To complete a context switch we need to save the CPU state for the process coming off the CPU and then load the state for the incoming process before allowing the CPU to execute the incoming process.
7.1. The Process Abstraction#
So far our discussion has remained fairly high level, but we need to concretely define what all of this process state actually is in order to be able to save it for a context switch. If a process is simply the execution of a program, what parts of the computer might be important to the state of a process? We need to capture any non-durable data used by this process, so memory is part of process state. CPU registers are also modified during execution, so their contents are part of process state. In order to pause the execution of a process we need to save that process’s view of memory and the contents of all the CPU registers where it was executing. Saving register contents is fairly simple, the OS copies them into a data structure associated with this process so they are saved for later retrieval. However, memory is slightly harder. As we will cover later in this book, we use virtualization of memory to provide each process with the illusion that it has an almost limitless amount of memory to work with. This virtual memory is encapsulated in a process address space or its view of memory.
Now that we have a collection of things we need to keep together for this process we need to introduce a data structure to contain them. Generically we use a process control block or PCB to keep these related objects together. In Linux, this structure is call the task_struct, so let’s take a quick look.
// Defined in include/linux/sched.h
struct task_struct {
//...
struct mm_struct *mm;
// ...
/* CPU-specific state of this task: */
struct thread_struct thread;
}
The actual task_struct is quite a bit larger, but for our simplified explanation, these two fields are the ones we care about. The mm_struct contains the view of memory for this process and the thread_struct contains space to save register values when a process is paused for scheduling. So when the OS decides that a process needs to be removed from the CPU and replaced with another, waiting process it uses these fields to save process state and uses the fields from another task to populate the CPU registers and view of memory before resuming its execution. The relationship is shown in figure Fig. 7.1.
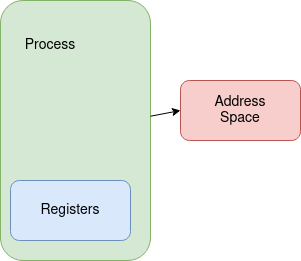
Fig. 7.1 A visual representation of a process#
To tie this back to our introduction, let’s look at this process representation and connect it to our hardware in Fig. 7.2.
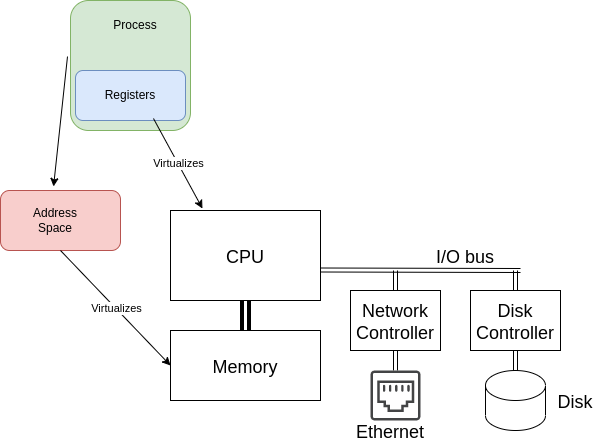
Fig. 7.2 The process illustration with the relevant parts connected to the hardware that they ‘virtualize’. The Registers data structure captures all the necessary state to virtualize the CPU and the address space does the same for memory.#
7.2. Creating a New Process#
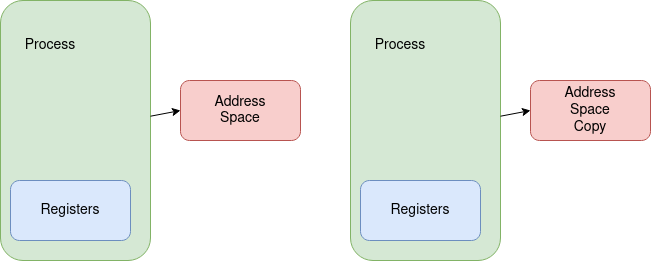
As we discussed earlier in Section 4.2.2, we create a new process with the fork() system call. This call instructs the operating system to create a new PCB based on the the active PCB when fork() is called. When discussing fork(), we typically refer to the process calling fork() as the parent process and the newly created process as the child process. The child process contains a new address space that is based on the one from the parent. We will discuss how this is done in a later chapter, but even though the new address space is based on the one from the parent process, the two processes do not share memory.
7.3. How are threads different?#
A core part of the UNIX model is separation of processes, or to be more specific, one running process should not be able to directly interact with the resources (memory, etc.) owned by another process without explicitly being setup to do so. This model is great for simple processes which do not need to utilize multiple CPUs, but it can make writing programs to use multiple CPUs more difficult as memory must be explicitly shared or processes must use another form of communication. A thread is like a process in that it has its own PCB, however, unlike a process it does not have its own address space. Instead threads all belong to a process and share the address space of that process so any changes made to memory by one thread are visible to all the other threads belonging to the same process. From the task_struct above, what this means is that the mm pointer in the task creating a new thread is used directly in the child thread instead of making a new copy of the structure. Figure Fig. 7.3 shows the difference from a forked process.
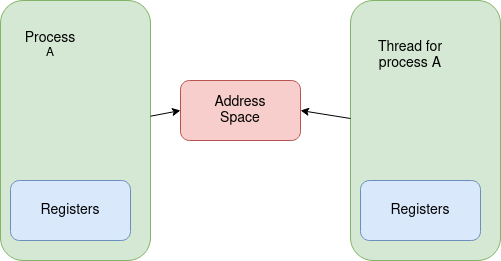
Fig. 7.3 How is a thread different from a process?#