Disk Layout:Implementing Name Space
Contents
16. Disk Layout:Implementing Name Space#
As we discussed in the file system abstractions, the name space is created by having directories, where a directory as shown in Fig. 16.1, is just another file that has strings and information about the files those strings represent.
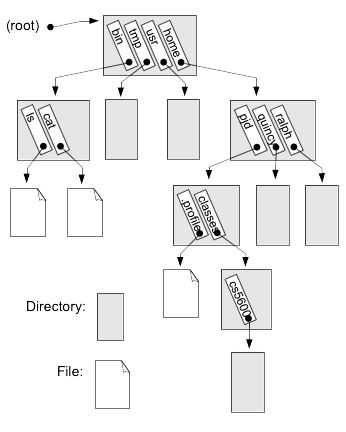
Fig. 16.1 Implementation view: hierarchical file system name space. Gray blocks are directories that contain entries with strings and corresponding inode numbers that identify the files.#
A simple way to implement such a directory (Fig. 16.2a), is to have a fixed array of data structures, where each entry has room for a fixed-size string, and the attributes of the file such as permissions, owner, and location of file on disk. This approach is used in the MS-DOS, and CDROM file systems described earlier. With these file systems, there is only one name for each file, and attributes identify if an entry is valid or not.
For Unix file systems, the directory typically does not contain the attributes, but instead contains an inode number (Fig. 16.2b) that identifies the inode that contains those attributes; this approach enables multiple directory entries to reference the same file. The separation of name (i.e., directory entry) and attributes (the inode and the blocks it points to) allows files to have multiple names, which for historical reasons are called hard links.

Fig. 16.2 Structure of a simplified directory with fixed-size file names where attributes are stored in the directory or in an external inode#
The directory structure above could be implemented with the following data structure in Listing 16.1:
struct dentry {
// inode number
unsigned int inode;
// file name, max 252 chars
char name[252];
};
This simple directory entry structure supports files with string names that can be up to 252 characters, and an inode number. Assuming 4-byte integers, one directory entry takes up 256 bytes. When searching for a file, the directory block(s) are read into memory and a linear search through the entries is used to locate the file. The alignment to 256 bytes (i.e., the somewhat strange length of the string name) ensures that when the entry is loaded into memory, the 4 byte inode is aligned to 4 bytes; so the processor can load it with a single memory load. The 256-byte entry size also ensures that directory entries are never split across file system blocks. For example, with a 4 K block size, one directory block will hold exactly 16 of these 256-byte directory entries. A simple fixed-size data structure like this is easy to manage: a new file is added by searching for an entry with an invalid attribute, and deleting a file just sets the attribute to invalid.
With the above data structure, all file names are limited to at most 252 characters, and more importantly, you are wasting a great deal of space for most files that have short names. More sophisticated file systems use structures like the ext2 file system shown below in Listing 16.2:
struct ext2_dir_entry {
// inode number
unsigned int inode;
// directory entry length
unsigned short rec_len;
// name length
unsigned char name_len;
// file type
unsigned char file_type;
// file name, max 255 chars
char name[];
};
In this case, the name of the file is variable length, with the length of the string specified by name_len. The rec_len describes how big the record is. The rec_len may include padding to ensure that entries are aligned to 4-byte boundaries. The last entry’s rec_len can be set to the remainder of the size of the directory block, and if a file is unlinked from a directory, the previous entry’s rec_len can be padded by the size of the record being removed. This enables the file system to add a new file to the directory by comparing the rec_len and the name_len to identify if there is enough unused space between the used part of a directory entry and the next to insert the file.
16.1. Smarter Directories#
From your data structures class, you should realize that linear search isn’t an optimal algorithm for searching, but it’s simple, robust, and fast enough for small directories, where the primary cost is retrieving a block of data from the disk. As an example, a local machine of the author has has 94,944 directories that use a single 4 KB block, another 957 directories that use 2 to 5 blocks, and only 125 directories that are larger than 5 blocks. In other words, for the 99% of the directories that fit within a single 4 KB block, a more complex algorithm would not reduce the amount of data read from disk, and the difference between \(O(N)\) and \(O(logN)\) algorithms when searching a single block is negligible.
However, the largest directories are actually quite big: the largest on this machine, for example, has 13,748 entries; another system contains about 64,000 files with long file names, or roughly 4000 blocks (16 MB) of directory data. Since directories tend to grow slowly, these blocks were probably allocated a few at a time, resulting in hundreds or thousands of disk seeks to read the entire directory into memory. At 15 ms per seek, this could require 10-30 seconds or more, and once the data was cached in memory, linear search in a 16 MB array will probably take a millisecond or two.
To allow directories with tens of thousands of files or more, modern file systems tend to use more advanced data structures for their directories. NTFS and Btrfs use B-trees, a form of a balanced tree. Other file systems, like Sun ZFS, use hash tables for their directories, while ext4 uses a hybrid hash/tree structure.