Operating System Abstractions
Contents
4. Operating System Abstractions#
UNIX has instilled in generations of engineers a basic aesthetic for how to design and structure complicated collections of software. In particular one learns that the designers of UNIX tried to structure the system around a small core set of ideas, “abstractions”, that once understood allows a programmer to understand the rest of the system and how to get things done.
We first describe the fundamental abstraction of files, which is central to Unix’s ability to compose programs together, and how this enables powerful functionality to be implemented in a shell. We then, using a shell as an example, briefly discuss key abstractions and the interfaces a shell uses to control processes, enable processes to communicate, operate on files in a file system and find out what happened to processes it started.
4.1. Everything is a file#
A core idea of Unix is that everything is a file, where a file is a stream of bytes. As shown in Fig. 4.1, the kernel maintains for each process a file descriptor table, where a file descriptor is an index into that table that can be used to read or write to a particular file. The system calls that work on all files are:
n = write(desc, buffer, len): Writelenbytes (or fewer if no more space is available) frombufferinto a stream identified bydescand return the actual number of bytes written,n.n = read(desc, buffer, max): Readmaxbytes (or fewer if no more data is available) from stream identified bydescintobufferand return the actual number of bytes read,n.
To understand how to use these operations, you really need to read the manual. In Linux you can find out about everything using the man program. For example, man 2 write tells you everything about the write system call:
Note
In this case, the 2 refers to the section of the manual for system calls. To find out about the different sections, you, of course, read the manual about the man command.
To make files in the file system look like a stream, on each read or write operation, the kernel increases a (per open file) offset by the amount of data read or written. It turns out that this naturally matches many applications that read or write files in their entirety.
Entries are added to the file descriptor table by operations that open or create a regular file, or create a special file like a network connection or a tty. There are three special file descriptors shown in Table 4.1, that programs (and libraries) should use for input, output and errors.
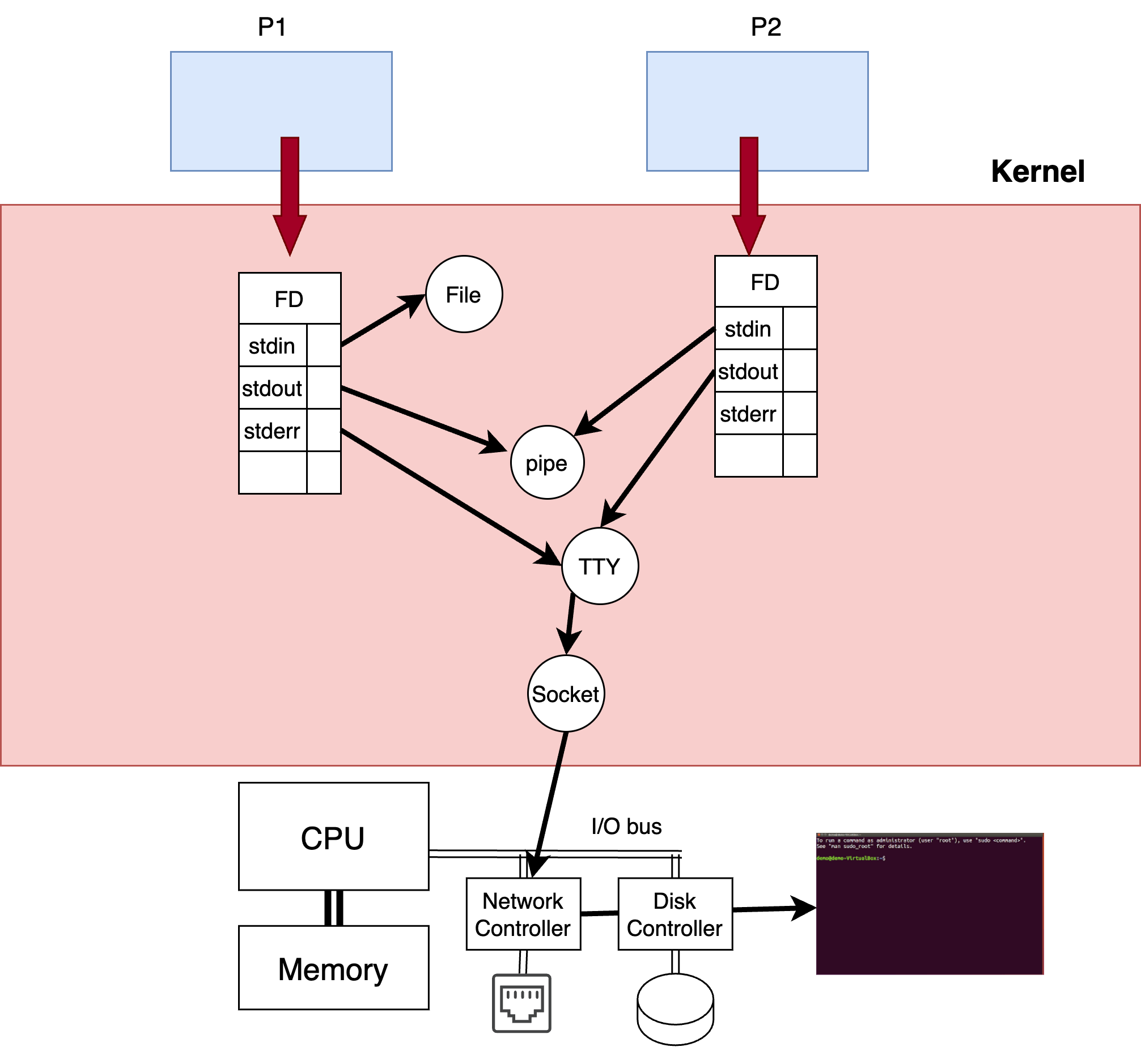
Fig. 4.1 The kernel maintains for each process an array of file descriptors, where a process can read or write to any kind of I/O object that is open in its table.#
Value |
Name |
Purpose |
|---|---|---|
0 |
stdin |
standard input; process should read data from here |
1 |
stdout |
standard output; process will write its output here |
2 |
stderr |
standard error; process should write out errors here |
So, for example, the following program echos a string to the terminal, which is the default stream for stdout and stdin:
While the same program can have its output redirected to a file:
And we can see that the contents of this file are the same as what was previously written to the terminal by using the cat program, which writes the contents of a file to its stdout, i.e., the terminal:
Note
This probably seems obvious to a modern reader, i.e., an object-oriented design, where you can do the same operations on any object. However, at the time, it was a radical idea when operating systems had specialized interfaces for files with records, devices such as terminals, etc…
This fundamental idea introduced by UNIX, that you can use the same read and write operations on any kind of I/O object, is very powerful. It enables a single program, depending on how it is launched by the shell, to work on data stored in a file system, data entered on a keyboard, or even on data sent over a network by other processes. By introducing the idea of a special file object called a pipe, you could allow programs to be combined together to do much more powerful tasks. The | symbol tells the shell to create a pipe that connects the output of one program to the input of the next program. So, let’s say we are trying to find all the programs on our computer that have anything to do with perl; the following command will: 1) list the contents of the /usr/bin/ directory, 2) send the output of that listing to a grep program that searches for the word perl, and 3) send the output of that grep to a program that counts the number of lines of input received.
Today, the idea of everything is a file has been taken much further in Linux. Linux now exposes all kinds of information through synthetic file systems, giving users and administrators massive ability to automate. For example, in the bash shell we are using $$ lets us know the id of the bash process itself. So, stealing a nice example from jonathan, the following command shows a portion of the open file table for the bash process that executes the command:
We can see that file descriptors 0, 1 and 2 (stdin, stdout and stderr) all refer to the same file, and we can learn more about this file using another command:
Now we can see that our stdin, stdout, and stderr all point to a character special file, which is used to represent a terminal in Unix. We can write to that same special device and it will appear in our terminal.
I would strongly encourage reading the shell and Unix sections of Under the Covers: The Secret Life of Software for a much more detailed coverage of this material. However, hopefully this has given you enough information to understand the power Unix unleashed by introducing polymorphism in the operating system, and creating a shell that enables you to combine all kinds of programs together in complicated ways.
The remainder of this chapter introduces the core abstractions of Unix, and the system calls you use on those examples, all with examples from a shell. By the end of this chapter, you should understand how a shell can start and control the execution of other programs, including how the stdin, stdout, and stderr I/O streams used by a process can be manipulated to enable the seamless composition of programs.
4.2. Process management#
As discussed previously, a process is a virtual computer, and the kernel provides each process with: 1) an abstraction of an isolated CPU (while multiplexing the physical CPU between different processes), 2) a virtual memory abstraction of massive contiguous memory that starts at address 0x0, and 3) a set of file abstractions that allow the process to persist data and communicate with other processes. After discussing the state maintained by the kernel, we discuss the interfaces the shell (or any application) can use to manipulate processes.
4.2.1. State#
As shown in Fig. 4.2, the kernel maintains a table of all processes, indexed by the process id, or PID, to keep track of all the information about each process. This includes a pointer to the file descriptor table (discussed earlier), as well as data structures to maintain CPU and memory management state. For CPU state, this includes all the registers that need to be loaded when the process runs.
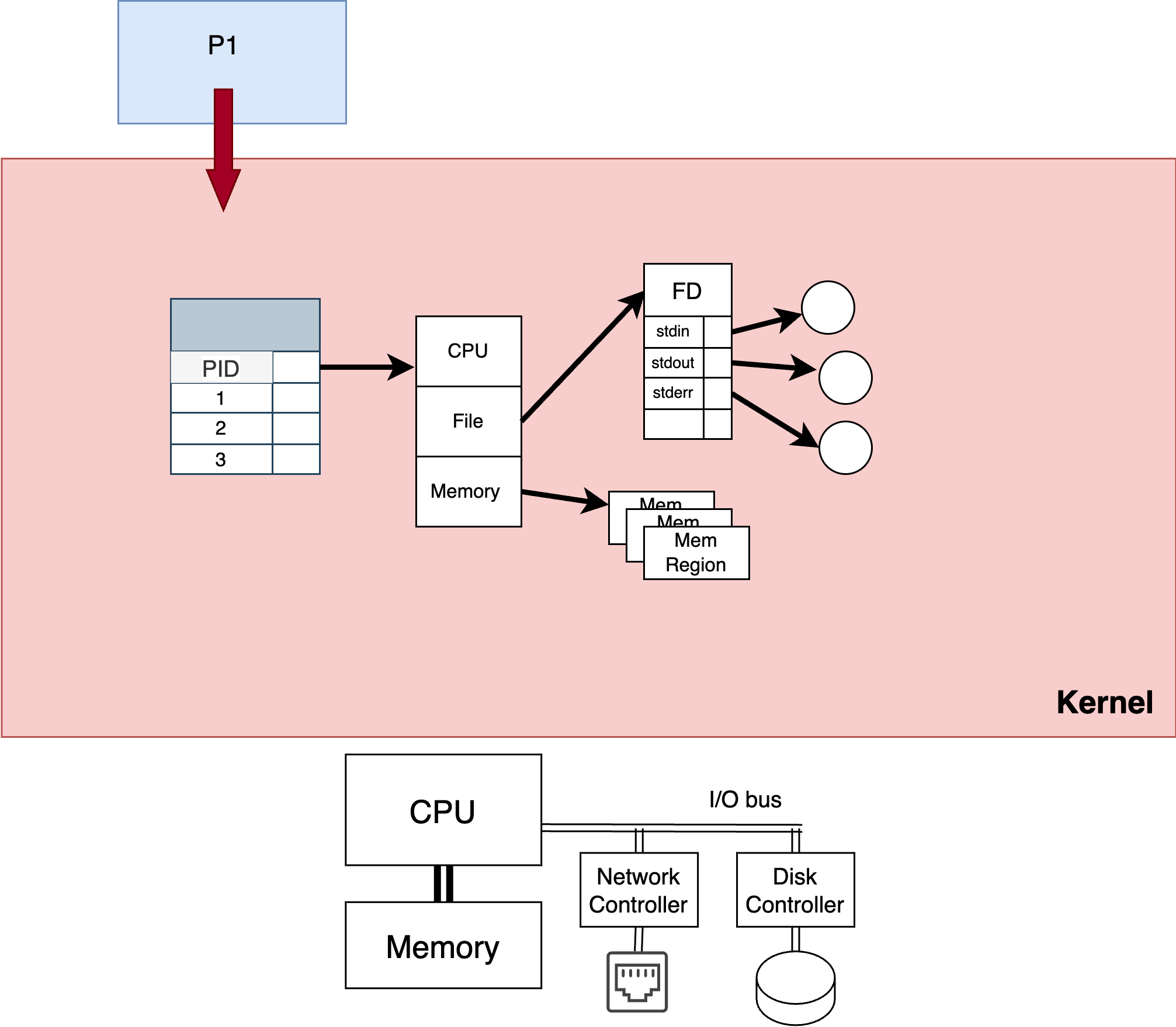
Fig. 4.2 A process table in the kernel, indexed by PID, points to the file descriptor table, memory management regions, and CPU state.#
In today’s computers, the address space, or virtual memory, of a process is a huge contiguous abstraction of memory that extends across addresses 0 to \(2^{64}-1\). As shown in Fig. 4.3, it is typically divided into code or machine-language instructions (for some reason typically called “text”), initialized data, consisting of read-only and read-write initialized data, initialized-zero data, called “BSS” for obscure historical reasons, heap or dynamically allocated memory, and stack. The memory regions referred to in Fig. 4.3 keep track of each of these regions.
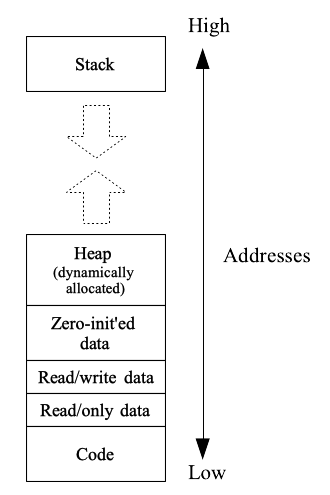
Fig. 4.3 Virtual memory layout#
4.2.2. System calls#
Key system calls in traditional Unix related to processes are:
pid = fork(void): Create a child process that is a duplicate of the parent; return 0 in child, andPIDof child in parent.exit(status): Terminate the calling process and record the status passed in for others.pid = waitpid(cpid, *status...): Wait for specified child processcpidto complete (or change state), fill*statuswith the status passed on child’s exit, and garbage collect any kernel resources; return thePIDof the child process that exited (or changed state).err = execve(program, arguments, environment): start executing a new process with specified arguments and environment information
The fork system call duplicates the calling process (referred to as the parent) into a new child process, where the only difference that enables the parent and child to distinguish themself is the return value. You can think of this logically as creating a copy of all the process memory, copying the CPU state, and copying the file descriptor table (while incrementing reference counts on all the files pointed to by the file descriptor table).
Unix maintains a process tree in the kernel, where every process has a parent, and a parent may have many children. For example, below I run the bash shell several times, and then print out the process tree (see man ps for arguments). You can see that ps is a child of bash, which is a child of bash, and so on.
The exit system call causes the process to complete, passing in a status for the reason and waitpid waits for a process to change state, and if it has exited, returns the status passed in by exit. While most of the process state is freed (e.g., the file descriptor table and memory regions) by exit, the process descriptor stays around to keep track of this status information. As a result, if another process does not do a wait on a process, it will become a zombie (yes, that is a real Unix term) holding on to a process descriptor in the kernel forever.
The execve system call executes a new program replacing the memory regions (BSS, text, …) of the calling process with memory from the file which the program argument points to. The CPU state is set to pass in the arguments, and the file descriptor table is not modified. Note, exec will never return unless there was some kind of failure; it is the same process just executing a different program.
4.2.3. Examples#
Okay let’s look at some code to better understand how these process-related system calls are used, starting with fork().
1#include <sys/types.h>
2#include <unistd.h>
3#include <stdio.h>
4#include <stdlib.h>
5
6int
7main(int argc, char* argv[])
8{
9 pid_t mypid, cpid, ppid;
10 cpid = fork();
11 ppid = getppid();
12 mypid = getpid();
13
14 if (cpid > 0) {
15 /* Parent code */
16 printf("hello, from parent with pid %d, pid of child is %d\n", mypid, cpid);
17 } else if (cpid == 0) {
18 /* Child code */
19 printf("hello, I am child with pid %d, my parent is %d\n", mypid, ppid);
20 } else {
21 perror("fork failed\n");
22 exit(-1);
23 }
24 return 0;
25}
The result of running the code in Listing 4.1 is:
The parent prints out the child pid that it gets from fork, and then its pid (from calling getpid()). You can see that these values match the pid that the child gets from getppid(). Again, please use man to find out about any of these system calls.
To see how one can use the combination of fork and exec to start a new program, and wait until that program completes, see Listing 4.2 below. Note that it is an error if the procedure returns from exec. Also, note that the parent explicitly waits for the pid of the child returned by fork on line 22, and then returns that status.
1#include <sys/types.h>
2#include <unistd.h>
3#include <stdio.h>
4#include <stdlib.h>
5#include <sys/wait.h>
6#include "doforke.h"
7
8
9int
10do_fork_exec(char *prog, char *const argv[])
11{
12 pid_t cpid;
13 int status=0;
14 cpid = fork();
15 if (cpid < 0) {
16 perror("fork failed\n");
17 exit(-1);
18 }
19
20 if (cpid != 0) {
21 // parent code, we need to wait for child
22 waitpid(cpid,&status,0);
23 } else {
24 execve(prog, argv, 0);
25 perror("should never get here\n");
26 }
27 return status;
28}
4.2.4. Summary#
So, you should now understand the abstraction of a process as a virtual computer, with CPU state and virtual memory. A process (parent) can create another process (child) by calling fork which causes the kernel to create a child with a duplicate of the CPU state and virtual memory of the parent. The child, like children everywhere, can decide to be different from its parent by exec of a different program. In that case the kernel looks at the program, and creates a new virtual address space by loading (potentially lazily as we will see) the text, initialized, and uninitialized data segments of the program into memory. You can now see how to implement the core part of any shell, reading from stdin the names of programs to execute, and creating new processes to execute those programs.
4.3. File system#
Normally, the programs to be executed come out of a file system, and we are often using redirection (e.g., >) to set the input or output of the program into some file in a file system. We will discuss later in much more detail the abstractions of a file system, but for now we briefly introduce the key information you need to know. First, it is important to realize that all Unix file systems organize information in a hierarchy as shown in Fig. 4.4.
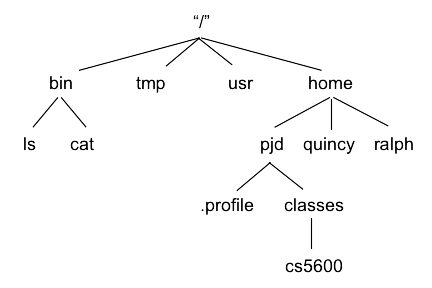
Fig. 4.4 Logical view: hierarchical file system name space#
We talked earlier about doing an exec, and with the execve call above, you need to specify the absolute path name to the program being executed. For example, if you want to run the cat program, the argument to execve on our system would be /usr/bin/cat.
You can tell the shell where to search for executable programs by specifying a PATH environment variable. For example, the following echo tells you the list of directories where the shell should look for executables, such as the program cat. The subsequent type command tells you where the shell will find an executable for cat.
Notice that the path to cat appears in the PATH variable shown by the echo command. So, a shell could go through each element of the path environment variable searching for a program. Thankfully, there is a whole family of library calls built on top of the execve system call that does this work for you (see execlp from the man page below, for example).
Some of the system calls specific to file systems are:
int desc = open(pathname, O_READ): Verify that filenameexists and may be read, and then return a descriptor which may be used to refer to that file when reading it.int desc = open(pathname, O_WRITE | flags, mode): Verify permissions and opennamefor writing, creating it (or erasing existing contents) if necessary as specified inflags. Returns a descriptor which may be used for writing to that file.close(desc): stop using this descriptor, decrement reference count in the file, and, if the reference count is zero, free any resources allocated for it.
Every process has associated with it a current working directory . If the pathname argument to open starts with a /, then it is an absolute path from the top of the file tree. If it doesn’t, then it is interpreted relative to the current working directory. This is convenient, since often you are doing all your work in your own directory, and you don’t need to figure out where that is in the whole file system.
A close call tells the kernel you are not using a file anymore, However, the kernel can’t free up resources until the reference count goes to zero, since others may be using the same file. On a fork, the kernel increments a reference count on each of the files, since now both the parent and child processes have it open, and both the parent and the child should close the file.
4.4. Changing stdin and stdout#
So far, we have seen how a shell can start another process (via fork) and how this child process can start running a different program (via exec), as well as how to open a file in the file system. Recall that the shell process has file descriptors 0, 1 and 2 (stdin, stdout and stderr) pointing to a character special file that represents a terminal, meaning that its input comes from a user typing characters in the terminal, and its output is displayed in the terminal. Recall also that the open file table is copied to the child process on a fork and is unchanged by an exec, so the child process running the new program will also receive its input from, and send its output to, the same terminal.
Now we will see how to support the < and > I/O redirection operators in the shell, which allow a process to read its input from a file, or write its output to a file, respectively. All we need to do is get the kernel to change the file descriptor table, so that descriptors 0 or 1 point to the specified input or output files. We can also redirect the standard error output, descriptor 2, to a file in a similar way.
Whenever we need the kernel to do something on behalf of a process, we need a system call, and for this purpose we use the dup system calls:
err = dup(oldfd): creates a copy of the file descriptoroldfd, using the lowest-numbered unused file descriptor for the new descriptor.err = dup2(oldfd, newfd): creates a copy of the file descriptoroldfd, tonewfd; closingnewfdif there is already an entry there.
So, imagine we have the following shell script:
foo > /tmp/bar
The shell would:
forka child process to execute the programfooIn the child process:
opena file calledbarin the directory/tmpuse
dup2to modify itsstdoutto use the file descriptor returned by the openexecthe programfoo
Great, now we know how to write a shell that can start a process that writes data into a file or reads data from a file specified by the user. How do we get programs to talk to each other without staging it through a file?
4.5. Pipes#
A pipe is a Unix kernel abstraction to allow communication between processes. A read of the pipe will return data previously written to it in a first-in-first-out (FIFO) fashion. Pipes are unidirectional communication channels represented by a pair of file descriptors – data can only be written into one end of the pipe, and read out of the other end. A programmer can create a pipe, and then use operations that change the entries in the file descriptor table to tie the output of one program to the input of another.
A pipe is created with the following system call:
err = pipe(&fdpair[0]): creates a pipe wherefdpairis an array of two file descriptors returned by the kernel.
After this call, fdpair[0] will have the descriptor for the entry in the file descriptor table for the read end of the pipe, and fdpair[1] will refer to the write end of the pipe. Data written to the write end of the pipe is buffered by the kernel until it is read from the read end of the pipe. A read from an empty pipe will block until there is some data in it, and will then return the max of the buffered data and the request size of the read.
To see how this is used, look at the following code (stolen from the Linux man page for pipe) in Listing 4.3:
1#include <sys/types.h>
2#include <sys/wait.h>
3#include <stdio.h>
4#include <stdlib.h>
5#include <unistd.h>
6#include <string.h>
7
8int
9main(int argc, char *argv[])
10{
11 int pipefd[2];
12 pid_t cpid;
13 char buf;
14
15 if (argc != 2) {
16 fprintf(stderr, "Usage: %s <string>\n", argv[0]);
17 exit(EXIT_FAILURE);
18 }
19
20 if (pipe(pipefd) == -1) {
21 perror("pipe");
22 exit(EXIT_FAILURE);
23 }
24
25 cpid = fork();
26 if (cpid == -1) {
27 perror("fork");
28 exit(EXIT_FAILURE);
29 }
30
31 if (cpid == 0) { /* Child reads from pipe */
32 close(pipefd[1]); /* Close unused write end */
33
34 while (read(pipefd[0], &buf, 1) > 0)
35 write(STDOUT_FILENO, &buf, 1);
36
37 write(STDOUT_FILENO, "\n", 1);
38 close(pipefd[0]);
39 _exit(EXIT_SUCCESS);
40
41 } else { /* Parent writes argv[1] to pipe */
42 close(pipefd[0]); /* Close unused read end */
43 write(pipefd[1], argv[1], strlen(argv[1]));
44 close(pipefd[1]); /* Reader will see EOF */
45 wait(NULL); /* Wait for child */
46 exit(EXIT_SUCCESS);
47 }
48}
The child code just sits in a loop reading from the pipe and then writing to stdout (lines 34-35). The parent just writes its first argument (argv[1]) to the write side of the pipe (line 43).
Note, on line 32 and line 42, we see that each process closes the side of the pipe they are not using. This is important, since, as mentioned above, the reference counts for all the file descriptors are increased on a fork, so, after the fork both the parent and the child have both the read and write side of the pipe open. The only reason that the child process eventually gets a 0 result on a read (rather than blocking) is because all the references to the write side are closed after the parent executes line 44.
So, imagine we have the following shell script:
foo | bar
The shell would:
create a pipe
fork a process to execute foo, but before doing the
execthe process should usedup2to modify itsstdoutto be the write side of the pipefork a process to execute bar, and that child should use
dup2to modify itsstdinto the read side of the pipe before doing theexec.
Now we can start two processes, executing different programs, that talk directly to each other through a pipe. These programs don’t care that they are talking to each other, they work exactly the same way if they are talking to a terminal, a file or a pipe. Now we have all the pieces to write a shell that can compose different programs to, for example, tell me how many programs in /usr/bin have something to do with perl:
4.6. Signals protecting against dreaded zombies#
When we talked about processes, we wrote a well-behaved shell that started another process using fork and then waited for it to finish. What would happen if we didn’t wait? Both the shell and the program it started would run at the same time, or at least as we will talk about later, the kernel causes the hardware to take turns running one and then the other. This is exactly what the symbol & does, i.e., tells the shell to let the program run in parallel. As an example, if I am building something complicated, I will often do it in parallel while continuing to work on my shell, e.g., the following command runs make, redirecting all its output into the file RES, and then returns control to the user. You can every so often look at RES to see if the make is done.
While this is great for the user who can now use the shell to run multiple programs concurrently, there is a problem. If the child finishes, it will exit with its status, but it will become a zombie if the shell never waits for it. After a while, the system will be filled with zombies and come to a grinding halt.
The way Unix deals with this is by sending a signal to a parent process when a child finishes. A signal is, for a virtual computer, similar to what an interrupt is for a physical computer. It tells it that some event happened on the outside world that it might want to know about.
There are a large number of signals the system can tell you about, and you can find out more about all of them with man 7 signal. In this case, the shell should register a signal handler for the SIGCHLD signal using the sigaction system call.
sigaction(signum, act, &oldact);
The act points to a data structure struct sigaction that describes how the caller wants to handle the signal, including a pointer to a function that will be called when the signal signum is delivered to the process. If there was previously a handler registered, the oldact tells the caller what the old action was. This allows the shell to wait for zombie children in the signal handler function when it receives notification that a child process has exited.
4.7. Conclusion#
This chapter has given you a whirlwind tour of some of the key abstractions of Unix. A process is a virtual computer, with its own virtual CPU and virtual memory. You should know how to create a new process, and tell it to execute a program.
The power of Unix is the idea that we can combine many programs together, using a shell, where the input and output of processes can be set up to be the terminal, files, or pipes. You should have an idea now on some of the key system calls that enable a shell to do this. Later chapters will discuss in much more detail the abstraction of a CPU and how it is scheduled, how memory management works and the system calls you can use to control it, and how file systems work and their system calls.