Common Concurrency Bugs
Contents
36. Common Concurrency Bugs#
In the previous chapters, we have already seen some examples of how things can go wrong without correct synchronization. In this chapter, we examine the three most common types of concurrency bugs: atomicity violations, order violations, and deadlocks. We will also briefly discuss other, less common, concurrency bugs. We will focus on deadlocks, since we have already seen the tools needed to address the other two main types of bugs.
Our bug classifications, and real-world examples, are drawn from Lu et al.’s 2008 study of concurrency bugs [LPSZ08], which examined 105 randomly selected concurrency bugs drawn from the bug databases of four open-source applications (MySQL, Apache, Mozilla, and OpenOffice). In Table 36.1, we break down these bugs by category.
Bug Category |
Bug Count |
|---|---|
Deadlock |
31 |
Atomicity Violation |
51 |
Order Violation |
24 |
Other |
2 |
One key takeaway from this study is that concurrent programming is hard—even mature, widely used projects have concurrency bugs. Developing tools to help detect, diagnose, and correct these concurrency bugs is an active area of research, but so far, there is no silver bullet.
36.1. Atomicity Violations#
The desired serializability among multiple memory accesses is violated (i.e., a code region is intended to be atomic, but the atomicity is not enforced during execution).[LPSZ08]
Atomicity violations are related to data races, but they are not the same. A data race occurs when two or more threads have conflicting accesses to a shared variable without any synchronization, but in some cases this may be the programmer’s intent (not a bug). For example, we used a flag variable in Listing 34.16 to force the child threads to wait until the parent had finished creating all the threads. An atomicity violation occurs when some section of code needs to be atomic for correctness, but there is no synchronzation to ensure atomicity. In Fig. 36.1 we show a real-world example of an atomicity violation bug found in one version of MySQL. Here, the atomicity violation bug is also a data race, since the conflicting accesses to thd->proc_info are not separated by any synchronization. Programmers often mistakenly believe that short code sequences can’t be interrupted or interleaved, leading to atomicity violation bugs like the MySQL example. The solution is simple: introduce a lock to protect the proc_info and ensure the lock is acquired prior to checking if thd->proc_info is NULL, and released only after Thread 1 is done using thd->proc_info. (Thread 2 should also hold the lock when setting thd->proc_info to NULL.)
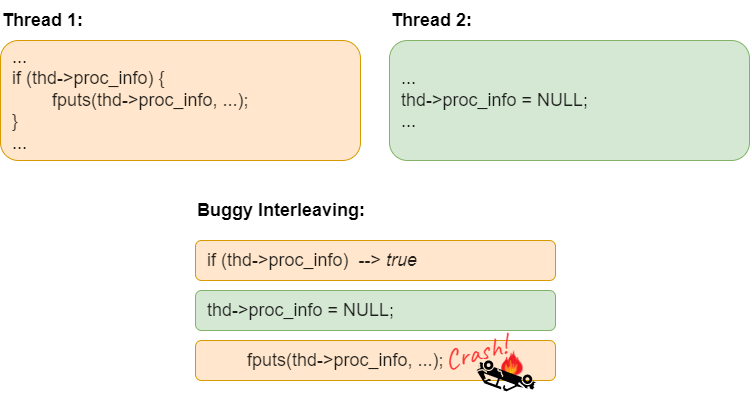
Fig. 36.1 Example of an atomicity violation bug from MySQL.#
We can also find atomicity violation bugs in data-race-free programs. For example, consider the attempt to add locking to the bank account deposit example from Listing 32.2, as shown in Fig. 36.2(a). Here, the programmer has ensured that all accesses to the shared data in the bank account are protected by a lock variable, however, they have not enforced the required atomicity. Because the lock is released after reading the old balance from the account, and re-acquired before writing the new balance, two threads can still interleave in a way that causes one of the deposits to be lost.
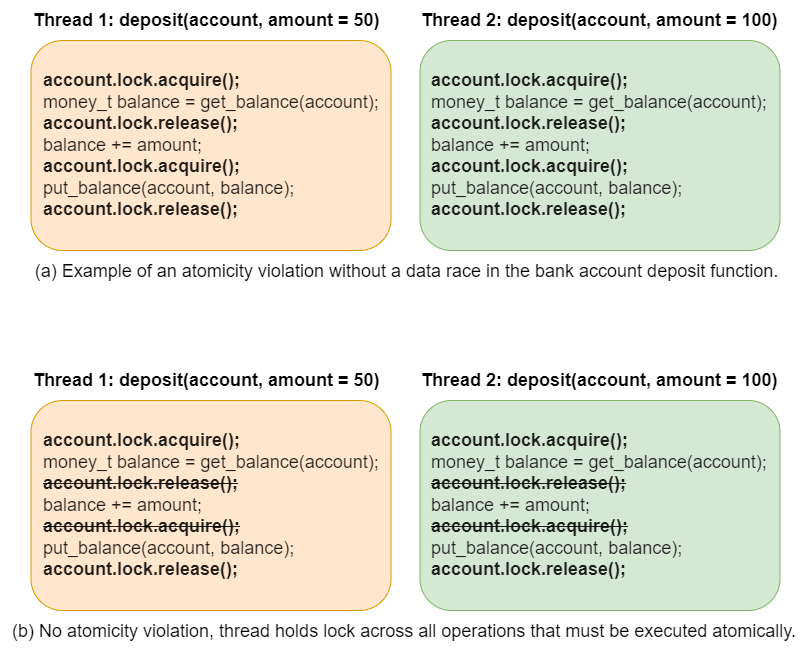
Fig. 36.2 Atomicity violation bug and its fix in a data-race-free implementation of the bank deposit function.#
When writing concurrent code, always think adversarially. Is your code guaranteed to execute correctly even if the scheduler switches between threads at the worst possible moment? Consider what operations must execute without interference—these sequences of instructions must have mutual exclusion enforced.
36.2. Order Violations#
The desired order between two (groups of) memory accesses is flipped (i.e., A should always be executed before B, but the order is not enforced during execution).[LPSZ08]
The producer / consumer bounded buffer problem demonstrated the need to enforce ordering between operations in different threads. However, programmers sometimes assume that operations in different threads must be ordered in some way without actually enforcing that order. This may occur because of assumptions about the relative speed at which threads are executing (e.g., if T1 has to perform a more complex calculation than T2, a programmer might assume that T2 will finish first). These assumptions are unsafe because a thread’s progress depends on many external factors, including how much time the scheduler gives it to run on a CPU and how many cache misses or page faults occur while it is running.

Fig. 36.3 Ordering violation bug in Mozilla.#
A real-world example of an order violation bug comes from Mozilla, and is illustrated in Fig. 36.3. In this example, Thread 1 is responsible for initialization and creation of other threads. Thread 2 is one of the threads created by Thread 1, and the programmers assumed that Thread 2 would have to run after Thread 1. Unfortunately, Thread 2 becomes runnable as soon as it is created, and may execute before Thread 1 assigns a value to the variable mThread. In the best case scenario, mThread will be NULL prior to the assignment in Thread 1, and Thread 2 will crash when it attempts to dereference mThread->mState. Why is this the best case? Because if mThread is non-NULL but not correctly initialized yet, then Thread 2 will set its mState from a random memory location and could continue to execute in unexpected ways for a long time without actually crashing. Crash failures are much easier to detect and debug than arbitrary incorrect behavior.
The fix for this bug is simply to enforce some ordering, so that Thread 2 has to wait until the initialization is complete. A semaphore with initial value 0 would work well for this purpose. Thread 2 issues a sem_wait() prior to accessing mThread, and Thread 1 issues a sem_post() when it is safe to use mThread.
36.3. Deadlocks#
A situation, typically one involving opposing parties, in which no progress can be made. (Oxford Languages definition)
A state in which each actor in a system is waiting on another actor to take action. (Computer systems definition)
An informal notion of deadlock is likely already familiar to you. Examples outside of computer systems include this amazing law passed by the Kansas State Legislature in the early 20th century:
When two trains approach each other at a crossing, both shall come to a full stop and neither shall start upon again until the other has gone.

Fig. 36.4 Two trains approaching each other at a crossing.#
Another real-world example of deadlock comes from the Massachusetts Driver’s Manual, Chapter 4, Rules of the Road:
Four-Way Stop
At an intersection with stop signs in all directions, you must yield the right-of-way to…
Another vehicle that has already come to a full stop
A vehicle directly to your right that has stopped at the same time as you
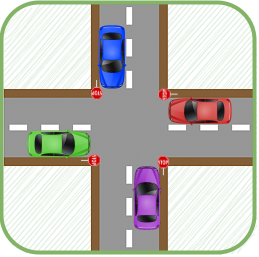
Fig. 36.5 Deadlock at a four-way stop caused by strictly following the rules of the road.#
As illustrated in Fig. 36.5, strictly following the rules of the road would result in a deadlock if four cars arrived at a four-way stop at exactly the same time. Each driver is required to yield to the vehicle on their right, so no driver is actually permitted to proceed through the intersection.
Since this is an operating systems book, our focus is on deadlocks that arise in the concurrent execution of computer programs. We will use the term thread to refer to the concurrent execution contexts, although the same issues arise when processes share resources.
36.3.1. What is a resource?#
In discussing deadlocks, we often talk about resources that are shared by multiple threads or processes in a computer system. In general, a resource is any object that is needed by a thread to do its work. Some resources may be physical objects, like a printer or a network card, while others are logical objects, like a counter variable, a scheduler queue, or a data structure representing a bank account record in a database. In fact, even the physical resources will be represented and managed by the computer system using some data structure. And, when we have a shared data object, we usually need to associate a lock with it to protect against unwanted interference. So, when we talk about resource deadlocks, we are often talking about the lock that protects that resource from concurrent access. When we say that a thread (or process) has been allocated (equivalently, assigned or granted) a resource, we often mean that the thread has acquired the lock protecting that resource, and is now permitted to use the resource.
We often find situations where threads need to acquire multiple resources protected by different locks. For example, consider the problem of transferring funds from one bank account to another. We want the entire transfer to happen atomically—either the funds are in the source account, meaning the transfer hasn’t happened yet, or the funds are in the destination account, meaning the transfer has been completed. If we had a single lock for the entire bank database, then all we need to do is acquire that lock, debit the source account and credit the destination account before releasing the lock. But since most operations access a single account (e.g., deposit, withdraw, read balance, etc.), this would give terrible performance to the bank customers. We really want to have a lock associated with each account, so that independent operations on different accounts can happen concurrently. Now the transfer operation needs to acquire locks for both the source and destination accounts and hold them until the balances of both accounts have been updated. Sample code for this setup is shown in Listing 36.1: we have a structure for each account which includes the account balance and a lock, and the transfer function must acquire the locks on both accounts before it updates the balances. As we will see, situations like this can easily lead to deadlocks.
1typedef struct account_s {
2 int acct_num;
3 money_t balance;
4 pthread_mutex_lock acct_lock;
5} account_t;
6
7void transfer(account_t *src_acct, account_t *dest_acct, money_t amount)
8{
9 pthread_mutex_lock(&src_acct->acct_lock);
10 pthread_mutex_lock(&dest_acct->acct_lock);
11
12 src_acct->balance -= amount;
13 dest_acct->balance += amount;
14
15 pthread_mutex_unlock(&dest_acct->acct_lock);
16 pthread_mutex_unlock(&src_acct->acct_lock);
17}
36.3.2. Visualizing and Modeling Deadlocks#
To visualize resource deadlocks, we adopt the directed bipartite graph model introduced by Holt [Hol72], in which threads and resources are represented by nodes, resource allocations are represented by a directed edge from the resource node to the thread node that has been granted exclusive use of that resource, and resource requests are represented by a directed edge from a thread node to the resource node that it is requesting. (We will only deal with the case where there is a single instance of each type of resource.) When drawing such a resource graph, we depict thread nodes using circles, and resource nodes using squares.
Fig. 36.6 shows an example resource allocation graph with two threads and two resources. Resource R1 has been allocated to thread T1, and resource R2 has been allocated to thread T2. Thread T1 has made a request for R2 (which cannot be granted until T2 releases it), and T2 has made a request for R1 (which cannot be granted until T1 releases it). These threads are deadlocked.
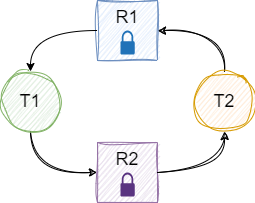
Fig. 36.6 Example of a resource allocation graph with a cycle, showing two threads and two resources; the threads are deadlocked.#
Returning to our bank transfer example, the situation in Fig. 36.6 could arise if R1 and R2 are accounts, and T1 is running transfer(R1, R2, amt1) while T2 is running transfer(R2, R1, amt2). In the transfer() function code, each thread first acquires the lock on the source account, so T1 locks R1 and T2 locks R2. Then, each thread attempts to acquire the lock on the destination account, so T1 blocks waiting for T2 to release R2, and T2 blocks waiting for T1 to release R1.
36.3.3. The Four Conditions for Deadlock#
Deadlocks in concurrent software systems were described by Djikstra [Dij65], who called them “the deadly embrace”. A few years later, Coffman et al. laid out the formal conditions for deadlock to occur [CES71]:
- Mutual exclusion
Threads are granted exclusive access to the resources they need; a resource that has been allocated to one thread cannot be used by any other thread.
- Hold and wait
A thread holding resources can request additional ones; if the additional resources are not available, the thread will wait for them while continuing to hold onto the resources it has already been granted.
- No preemption
Previously granted resources cannot be forcibly taken away from a thread; threads must voluntarily release resources when they are done using them.
- Circular wait
There exists a circular chain of threads, each of which is waiting for a resource held by the next member of the chain.
These conditions, taken together, are necessary and sufficient for deadlock. If we break one of the four conditions, then deadlock cannot occur. Let’s try attacking each condition in turn.
36.3.4. Breaking Mutual Exclusion#
Recall that we introduced mutual exclusion as one of the requirements for a solution to the critical section problem. Herlihy, however, showed that we can devise non-blocking algorithms to operate on concurrent data structures without enforcing mutual exclusion, given atomic hardware instructions such as compare-and-swap (CAS) [Her93] [Her90]. These algorithms and data structures are called lock-free if they guarantee that some thread will complete an operation in a finite number of steps taken by itself or other threads, and wait-free if they guarantee that each thread will complete an operation in a finite number of steps.
The basic idea behind lock-free synchronization is to attempt to make a change optimistically, assuming there will be no interference from other threads. If any interference happens there must be a way to detect and recover from it, usually by retrying the operation. The CAS(location, expected, new) atomic instruction (see Listing 34.8) has this flavor—if the specified memory location still contains the expected value, then there has been no interference, the memory location can be updated with the new value, and the CAS succeeds. If the CAS fails, then the operation must be retried.
For example, suppose we needed to implement an AtomicAdd() function. We saw earlier (Listing 32.5) that incrementing or decrementing a variable involves multiple steps, and so we used a lock to make those steps atomic.
pthread_mutex_t L = PTHREAD_MUTEX_INITIALIZER;
void AtomicAdd(int *val, int a)
{
pthread_mutex_lock(&L);
*val += a;
pthread_mutex_unlock(&L);
}
The overhead of acquiring and releasing the lock, however, far exceeds the work of the actual integer addition, making this a very inefficient solution. Using CAS we can avoid locking. The solution is shown below:
1void AtomicAdd(int *val, int a)
2{
3 do {
4 int old = *val;
5 int new = old + a;
6 } while (CAS(val, old, new) == false);
7}
A thread first reads the current value of the variable from the memory location, then adds the requested amount to obtain the new value. The CAS will succeed if the value stored in the memory location still matches the old value that was read. If another thread has managed to complete its own AtomicAdd on the same location between the read of the old value at line 4 and the CAS on line 6, then the memory location will no longer contain the old value, the CAS will fail (returning false) and the thread will return to line 4 for another attempt. We can see that the AtomicAdd() is lock-free, because some thread’s CAS must succeed. It is not wait-free, however, because an unlucky thread could retry an arbitrary number of times without completing its operation.
The CAS primitive suffers from what is called the ABA problem. Briefly, a CAS succeeds when the memory location contains the expected value, however, this does not mean that nothing has changed. It is possible for thread T1 to read a value A, thread T2 to change the value to B, and thread T3 to change the value back to A again before T1 attempts a CAS. T1’s CAS would succeed, even though the execution of other threads had been interleaved with its own accesses to the memory location. In the case of the AtomicAdd() shown above, this interleaving is harmless—so long as the current value matches what the thread read previously, the new value will be correct. In implementations of more complex data structures such as a non-blocking stack, however, more care is needed to correctly handle the ABA problem.
While non-blocking algorithms can prevent deadlocks by eliminating the mutual exclusion requirement, they are complex and hard to design. Efficient non-blocking algorithms exist for a handful of important data structures (e.g., stacks, queues, and linked lists) but there are many situations where they cannot be applied. Consider the bank account transfer() function, for example: we can easily update either account using our lock-free AtomicAdd(), but this doesn’t help us to atomically update both accounts. We are often stuck with the mutual exclusion requirement for correctness, so we must look elsewhere for a solution to deadlock.
We will discuss Read-Copy-Update (RCU), a widely used primitive that provides lock-free synchronization for readers of a data structure, later.
36.3.5. Breaking Hold-and-Wait#
If threads acquire all the resources they need before starting execution, then a thread will never have to wait for additional resources while holding onto resources it has already been granted. Once a thread is able to start running, it will have everything it needs to finish, making the resources available again for other threads. No deadlock! Unfortunately, there are several significant problems with this approach:
A thread with ‘large’ resource needs (e.g., many different locks) may have to wait for a long time for all resources to be available at the same time. Additional effort is needed to ensure these threads do not starve.
The system concurrency is limited because threads must acquire all resources before starting, rather than acquiring them when they needed. Consequently, resources are tied up for a longer time, even when they could be safely used by other threads.
A thread may not know all the resources that it will need before it even starts running. Particularly for interactive tasks, input from the user can heavily influence what resources are needed next.
As a general strategy, acquiring all resources before starting execution is not very promising, although it may be used in some specialized systems such as batch processing. Another way to break the hold-and-wait condition requires a thread to release all the resources it already holds before it can request an additional resource. The thread must then submit a batch request for all the resources it needs (the ones it just gave up, and the new resource). The thread will be blocked until the complete set of resources can be allocated to it, but it will not be holding any resources while it waits. This strategy does not prevent starvation of a thread that needs a large number of resources simultaneously, and it requires care on the part of the programmer to ensure that data structures are not left in an inconsistent state when the resources are released.
There is a lot of overhead in giving up existing resources (e.g., releasing all the locks already acquired) and then immediately asking for them back again, particularly when the additional resource was already available. To help with this situation, some thread libraries offer a trylock() function:
pthread_mutex_trylock(pthread_mutex_t *mutex): Acquire the lock referenced bymutexif it is available and return 0; ifmutexis currently locked, the call will return immediately with an error code.
A thread holding one or more locks already will first try to acquire an additional lock with a trylock() operation. If it succeeds, then there is no need to release the locks it already held. If the trylock() fails, however, the thread must release all of the other locks and try again to acquire the full set of locks. For example:
1void transfer(account_t *src_acct, account_t *dest_acct, money_t amount)
2{
3 pthread_mutex_lock(&src_acct->acct_lock);
4 while (pthread_mutex_trylock(&dest_acct->acct_lock) == EBUSY) {
5 pthread_mutex_unlock(&src_acct->acct_lock);
6 pthread_mutex_lock(&src_acct->acct_lock);
7 }
8
9 src_acct->balance -= amount;
10 dest_acct->balance += amount;
11
12 pthread_mutex_unlock(&dest_acct->acct_lock);
13 pthread_mutex_unlock(&src_acct->acct_lock);
14}
By releasing the source account lock on line 5 when the destination account is already locked by another thread, we prevent deadlock from occurring. There is, however, a new possibility of livelock in which our two threads performing conflicting transfers, T1 and T2, continually lock one account, find the second account locked by another thread, release their first lock and try again. Inserting some random delay between the release on line 5 and the re-acquisition on line 6 can reduce the likelihood that threads will repeatedly conflict in this way.
Two-Phase Locking
Breaking the hold-and-wait condition is related to two-phase locking, which is a common strategy in database systems. In two-phase locking, an operation that requires multiple locks executes first in a growing phase, and then in a shrinking phase. In Phase One (growing), the thread tries to acquire all the locks it needs, one at a time. If any lock is unavailable, then it releases all the locks and starts over. Once Phase One succeeds, the thread has all the locks it needs, and can start performing updates, after which it can release the locks. This version of two-phase locking prevents deadlocks by not allowing the hold-and-wait condition. (Note that in the database literature, two-phase locking is often described with hold-and-wait in Phase One. Deadlocks are thus possible, and the database system needs a strategy for detecting them and aborting one of the transactions that is involved in the deadlock cycle.)
36.3.6. Allowing Preemption (breaking the no preemption condition)#
For certain physical resources, we can prevent deadlock by forcibly preempting the resource from one thread and allocating it to another. In particular, this works for resources that we can virtualize so that each thread has the illusion of its own private copy of the resource. For example, a physical CPU can be allocated to one thread for a timeslice, then forcibly preempted and allocated to another thread. Similarly, a page of physical memory can be allocated to the use of one address space, then preempted and reallocated to the use of another address space. In both cases, this is feasible because we can save the state of the resource (in the thread struct for the CPU, or in the swap file for memory) when it is preempted from a thread, and restore the state when it is returned to the thread.
However, when we are dealing with shared data structures, breaking ‘no preemption’ is not a very appealing option. We don’t generally know the state of the data structure if we preempt a lock from a thread in the middle of a critical section, so we have no way of ensuring that the data is consistent before allowing another thread to access it. We also can’t guarantee that it is safe for the original thread to resume from the point at which it was preempted, and we have no way of rolling back or aborting the operation that the thread was in the middle of performing. In contrast, database systems include transactional logging mechanisms that make it possible to abort a transaction, preempting the locks that the transaction held and restoring the database to its pre-transaction state.
36.3.7. Breaking Circular Wait#
The final condition we have to consider is the circular wait. It is quite appealing to allow the first three conditions, since they all serve to make it easier to write correct concurrent code, while ensuring that we never find ourselves in a situation with a circular chain of threads holding some resources and waiting for a resource held by the next thread in the chain.
One idea that we can immediately reject is to prevent circular wait by only allowing a thread to request or hold one resource at a time. There are simply too many scenarios where a thread needs to use multiple resources together to accomplish the desired task, such as transferring between two bank accounts. The only feasible way to implement this idea is to have a ‘big giant lock’ that protects all the resources in the system that could possibly be used together. Then, threads would only need a single resource, namely the big giant lock. In our bank scenario, this would mean a single lock for all the bank accounts, but the resulting loss of concurrency would be unacceptable.
The other option is to provide a global ordering of resources, and require all threads to acquire resources according to this ordering. That is, a thread holding resource \(j\) cannot make a request for resource \(i\) where \(i\) < \(j\) in the global ordering. The resulting resource allocation graph is guaranteed to contain no cycles, and circular wait is impossible. There are several challenges with this idea in practice. The first is that it may be difficult to come up with a global ordering for a system when there are a large number of different resources. The second is that it relies on programmers to know and respect the global ordering when they write code. Nonetheless, it is a very widely used and effective strategy in practice.
Returning again to our bank transfer function, we can use the account numbers to define a global lock ordering: lower-numbered accounts precede higher-numbered accounts in the lock ordering. An example of this strategy is shown in Listing 36.3.
1void transfer(account_t *src_acct, account_t *dest_acct, money_t amount)
2{
3 if (src_acct->acct_num < dest_acct->acct_num) {
4 pthread_mutex_lock(&src_acct->acct_lock);
5 pthread_mutex_lock(&dest_acct->acct_lock);
6 } else {
7 pthread_mutex_lock(&dest_acct->acct_lock);
8 pthread_mutex_lock(&src_acct->acct_lock);
9 }
10
11 src_acct->balance -= amount;
12 dest_acct->balance += amount;
13
14 pthread_mutex_unlock(&dest_acct->acct_lock);
15 pthread_mutex_unlock(&src_acct->acct_lock);
16}
Now, if T1 is running transfer(R1, R2, amt1) while T2 is running transfer(R2, R1, amt2), the two threads must lock the accounts in the same order. Suppose R2 has a lower account number than R1. Then, T1 will execute lines 7-8, locking R2 first followed by R1, and T2 will execute lines 4-5, also locking R2 followed by R1. Whichever thread succeeds in locking R2 first will proceed to lock R1 and complete its transfer, releasing both the locks and allowing the other thread to proceed. Deadlock is prevented.
36.3.8. Reality Check#
No single strategy for dealing with deadlock is appropriate for all resources in all situations. Moreover, all strategies are costly in terms of computation overhead, or restricting the use of resources. Consequently, many systems make some use of what Tanenbaum refers to as “the ostrich algorithm”: ignore the problem and hope it doesn’t happen too often [TB14]. This isn’t really as shocking as it might sound at first. For personal computers, which are rebooted frequently, the rare inconvenience of manually resolving a deadlock (by forcibly killing some tasks, or rebooting the machine) is likely to be preferable to the constant overhead of ensuring deadlocks don’t occur. On the other hand, deadlocks are unacceptable in safety critical systems and ensuring they don’t occur is worth some loss in performance. Modern operating systems like Linux employ a mix of strategies for deadlock, including using lock-free algorithms when possible, defining a well-documented lock hierarchy that kernel programmers are expected to follow, and providing runtime lock validators that check for deadlocks or incorrect lock usage. Because of the high runtime cost, such validators are generally used during development but not in deployment.
36.4. Livelock, Starvation and Other Bugs#
While atomicity violations, order violations, and deadlocks collectively made up over 98% of the concurrency bugs in Lu et al.’s study [LPSZ08], there are other subtle concurrency issues that can occur.
In Section 36.3.5, we briefly mentioned livelock, which occurs when threads are running and changing state, but are not making progress towards completing an operation. The common example of a real-world livelock is when two people meet in a narrow corridor and each repeatedly steps aside in the same direction to let the other person pass. The trylock scenario is one way that livelock can occur in a computer system. More generally, livelocks can happen whenever threads continually retry a failed operation. For example, there is usually some limit on the number of files that a process can have open. Suppose this limit is set to 10 and we have a multithreaded process with 16 threads, each of which needs to open 2 files (say, to read its input and write its output). If a thread’s attempt to open a file fails because there are too many open files already (e.g., open() returns -1 with errno == EMFILE “Too many open files”), then the thread will simply try to open the file again, in the hopes that some other thread will finish, close its files, and allow this thread to proceed. Code for this is depicted in Listing 36.4. Now, if all available open files are used by threads that have opened their input files, no thread will be able to open an output file and complete its work. This scenario looks extremely similar to deadlock: we have a limited set of resources (slots in the open file table), all of the resources have been allocated to threads, and all of the threads are holding their resources while waiting for an additional resource that is held by another thread. The difference is that the threads are not blocked—they are repeatedly issuing an open() system call and getting a response, so work is being done, but the threads are not making any progress.
1void *threadfunc(void *arg)
2{
3 struct args_s *my_args = (struct args_s *)arg;
4
5 int fd_in;
6 int fd_out;
7
8 /* Open input file, retrying if there are too many files already open */
9 for ( ; ; ) {
10 fd_in = open(my_args->infile, O_RDONLY);
11 if (fd_in > 0) {
12 break;
13 }
14 if (errno != EMFILE) {
15 return NULL;
16 }
17 }
18
19 fprintf(stderr,"Thread %d has input file %s open now.\n",
20 my_args->id, my_args->infile);
21
22 /* Open output file, retrying if there are too many files already open */
23 for ( ; ; ) {
24 fd_out = open(my_args->outfile, O_RDWR);
25 if (fd_out > 0) {
26 break;
27 }
28 if (errno != EMFILE) {
29 close(fd_in);
30 return NULL;
31 }
32 }
33 fprintf(stderr,"Thread %d has output file %s open now.\n",
34 my_args->id, my_args->outfile);
35
36 /* Sleep for a while to simulate time reading input and producing output */
37 sleep(1);
38
39 close(fd_in);
40 close(fd_out);
41
42 return NULL;
43}
Another study of bugs in open source code [AASEH17] found that livelock bug reports were extremely rare (only 2 out of 351 concurrency-related bug reports). This may be because of the difficulty in diagnosing and reproducing livelocks, or because programmers were aware of the potential for livelock and took care to avoid it (for example, by setting a limit on the number of retries).
Starvation is distinct from deadlock and livelock, although, again, some thread (or threads) never receive the resources they need. The difference is that the resource(s) a thread is waiting for will repeatedly become free, but is always allocated to a different thread. We saw this in shortest-job-first scheduling, where an infinite sequence of short threads are always granted the CPU ahead of a long-running thread. Starvation may also occur if a thread has to give up all the resources (locks) it already holds before it is allowed to request more resources. Starvation related to synchronization can also occur with reader/writer locks, where threads that only need to read a data object can execute concurrently using a shared lock but threads that need to write the data object must obtain an exclusive lock, waiting for all readers to finish. Finally, starvation can occur due to characteristics of modern hardware that give some threads an advantage when competing for a lock, such as NUMA memory systems and caching.
Finally, there are concurrency bugs that are difficult to classify. Lu et al. provide one example from MySQL, where the developers included a watchdog thread to monitor other threads for potential deadlock. The monitor was designed to crash the server, forcing a restart, if it detected that some thread had waited for more than fatal_timeout to acquire a lock. A simplified version of this scenario is depicted in Fig. 36.7. Unfortunately, when the workload was high, there could be a very large number of worker threads and the lock wait time frequently exceeded the allowed timeout. The developers had not considered how to adjust the fatal timeout value based on the workload.

Fig. 36.7 Example of a concurrency-related bug from MySQL.#